Alok Upadhyay | February 2026
TL;DR: We test whether VLMs make logically consistent identity judgments in person re-identification. Non-degenerate VLMs show 14–26% symmetry violations and up to 38.5% transitivity violations. The most accurate model is the least logically consistent – revealing a fundamental accuracy-consistency trade-off.
Paper: Are VLM Identity Judgments Logically Consistent? (ICLR 2026 Workshop on Logical Reasoning of LLMs)
Code: github.com/alok-upadhyay/vlm-reid-consistency
The Question
If a vision-language model says Person A is Person B, should it not also say Person B is Person A? This seemingly trivial requirement – the symmetry of identity – is one of the most basic logical properties a reasoning system should satisfy. Yet, as we show in this paper, current VLMs routinely violate it.
We go further and ask: if a model says A = B and B = C, does it conclude A = C? This is transitivity – another elementary property of identity. And does chain-of-thought prompting help?
Why This Matters
Person re-identification (re-ID) – determining whether two images show the same individual – is critical in surveillance, forensics, and access control. Unlike open-ended VQA, re-ID produces a binary judgment (SAME or DIFFERENT) subject to well-defined logical constraints. This makes it an ideal test bed for probing whether VLMs reason coherently.
A surveillance system that asserts “A is B” in one image order but “A is not B” when reversed is not merely inaccurate – it is fundamentally incoherent. Accuracy alone is an insufficient measure of model quality for identity judgments.
The Setup
We formalize two necessary conditions for any identity judgment function $f$ to be logically coherent:
Symmetry: $f(\text{img}_A, \text{img}_B) = f(\text{img}_B, \text{img}_A)$ for all image pairs.
Transitivity: If $f(A,B) = \text{SAME}$ and $f(B,C) = \text{SAME}$, then $f(A,C) = \text{SAME}$.
We evaluated four open-source VLMs and one embedding baseline on Market-1501 (750 identities, ~13K images, 6 cameras):
| Model | Parameters | Type |
|---|---|---|
| Qwen2-VL-7B | 7B | Generative VLM |
| MiniCPM-V | 8B | Generative VLM |
| Llama-3.2-Vision | 11B | Generative VLM |
| LLaVA-NeXT-7B | 7B | Generative VLM |
| CLIP ViT-L/14 | 428M | Embedding similarity |
We sampled 400 image pairs for symmetry (queried in both orders = 800 queries) and 250 triplets for transitivity (750 queries), all at temperature 0 for reproducibility.
Finding 1: Half the VLMs Are Degenerate
Llama-3.2-Vision and LLaVA-NeXT-7B always predict DIFFERENT regardless of input – yielding trivial 100% symmetry but chance-level 50% accuracy. These models default to a conservative rejection strategy, making them useless for fine-grained identity matching.
Finding 2: The Accuracy-Consistency Trade-off
Among the non-degenerate models, a striking pattern emerges:
| Model | Accuracy (%) | Symmetry Rate (%) | TVR (%) |
|---|---|---|---|
| MiniCPM-V | 81.5 | 74.0 | 38.5 |
| Qwen2-VL-7B | 63.9 | 86.9 | 37.9 |
| CLIP ViT-L/14 | 52.6 | 100.0 | 2.5 |
The most accurate model (MiniCPM-V at 81.5%) has the lowest symmetry rate (74%) and the highest transitivity violation rate (38.5%). Meanwhile, the perfectly symmetric CLIP baseline achieves only 52.6% accuracy.
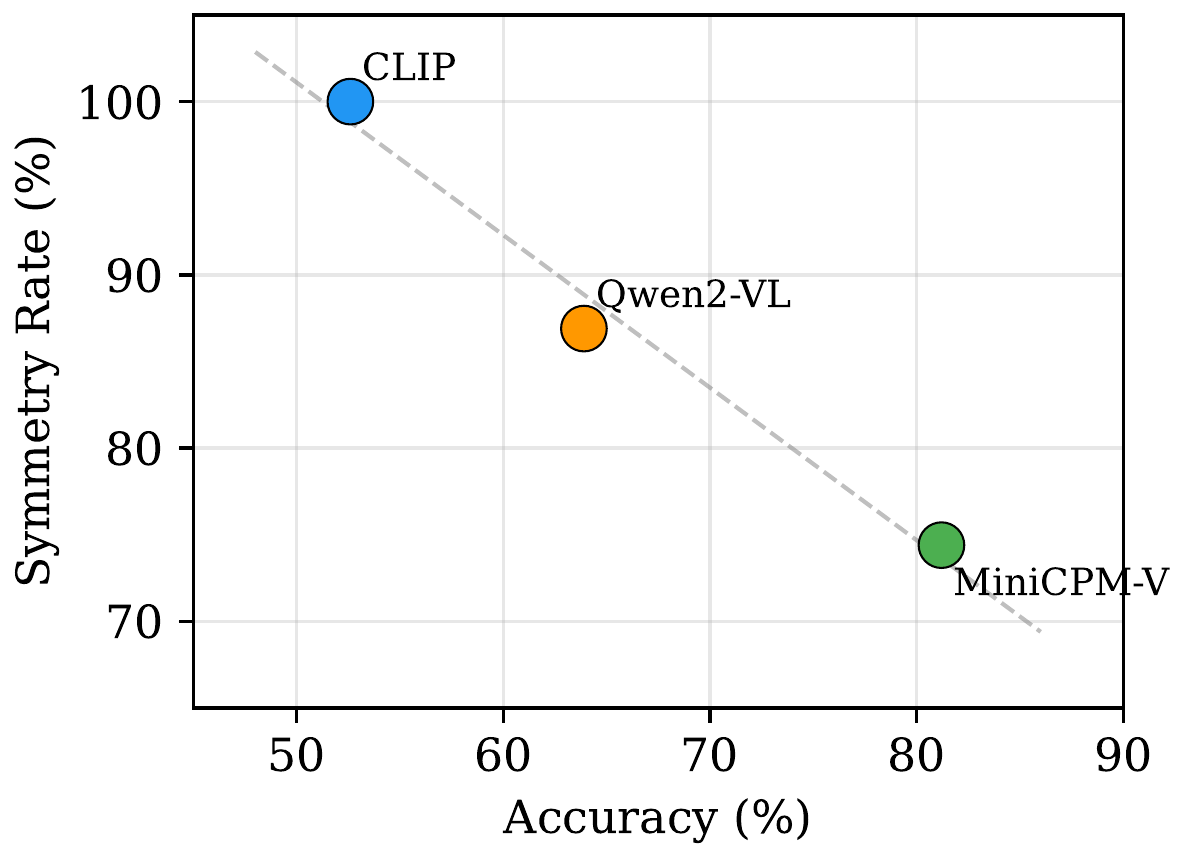 Accuracy versus symmetry rate across models. Higher accuracy is associated with lower logical consistency among the non-degenerate models.
Accuracy versus symmetry rate across models. Higher accuracy is associated with lower logical consistency among the non-degenerate models.
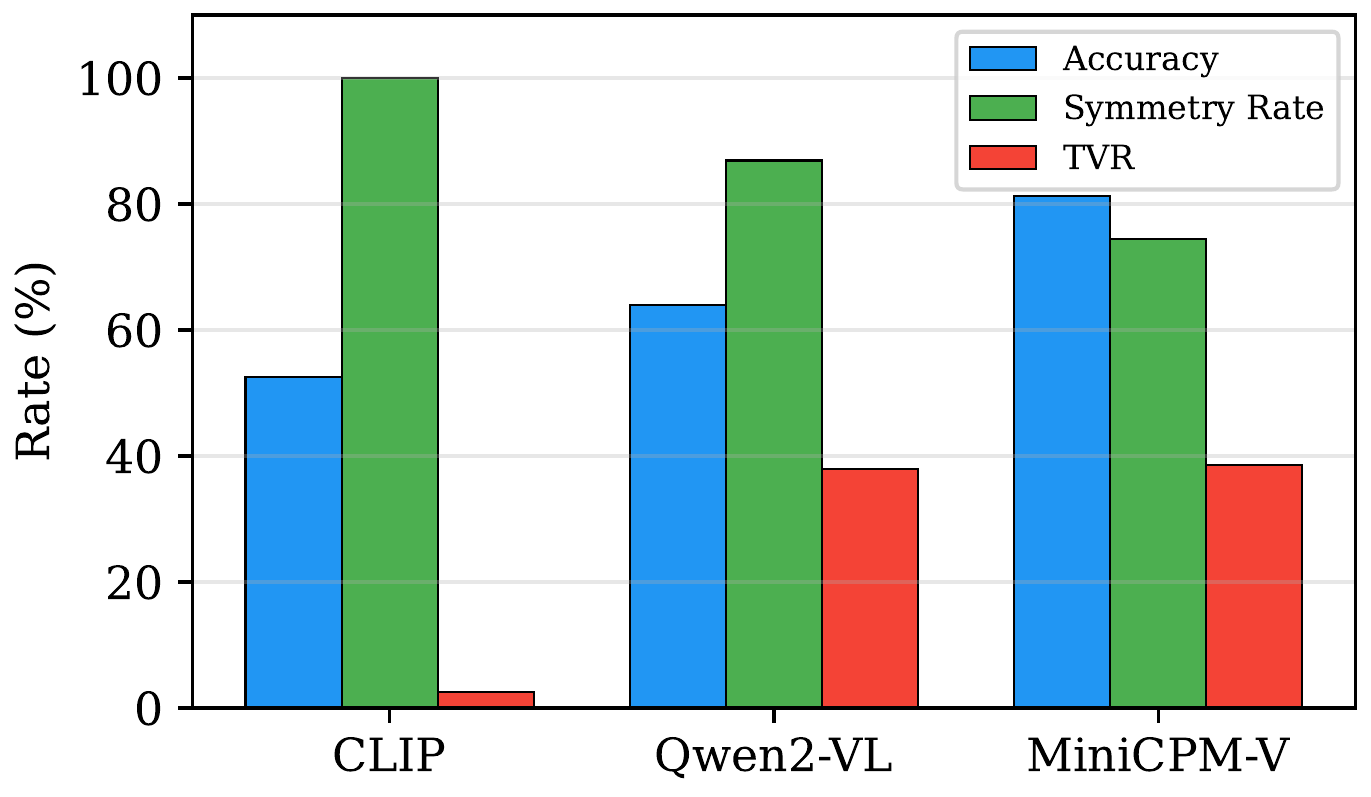 The accuracy-consistency trade-off. Models that achieve higher pairwise accuracy exhibit lower symmetry rates and higher transitivity violation rates – improved visual discrimination comes at the cost of logical coherence.
The accuracy-consistency trade-off. Models that achieve higher pairwise accuracy exhibit lower symmetry rates and higher transitivity violation rates – improved visual discrimination comes at the cost of logical coherence.
Finding 3: Transitivity Is Harder Than Symmetry
Transitivity violations are substantially more prevalent than symmetry violations. MiniCPM-V’s 38.5% TVR means more than a third of applicable triplets violate transitivity. Each pairwise judgment is made independently with no mechanism to enforce global consistency – the model can judge A = B and B = C based on locally sufficient evidence while failing to recognize that A and C share identity under different conditions.
CLIP’s low TVR (2.5%) demonstrates that embedding-based methods maintain global consistency far better than generative VLMs. But even CLIP isn’t perfect: thresholding cosine similarity doesn’t guarantee transitivity since $\text{sim}(A,B) > \tau$ and $\text{sim}(B,C) > \tau$ can coexist with $\text{sim}(A,C) < \tau$.
Finding 4: Chain-of-Thought Has Mixed Effects
We tested whether step-by-step reasoning improves logical coherence:
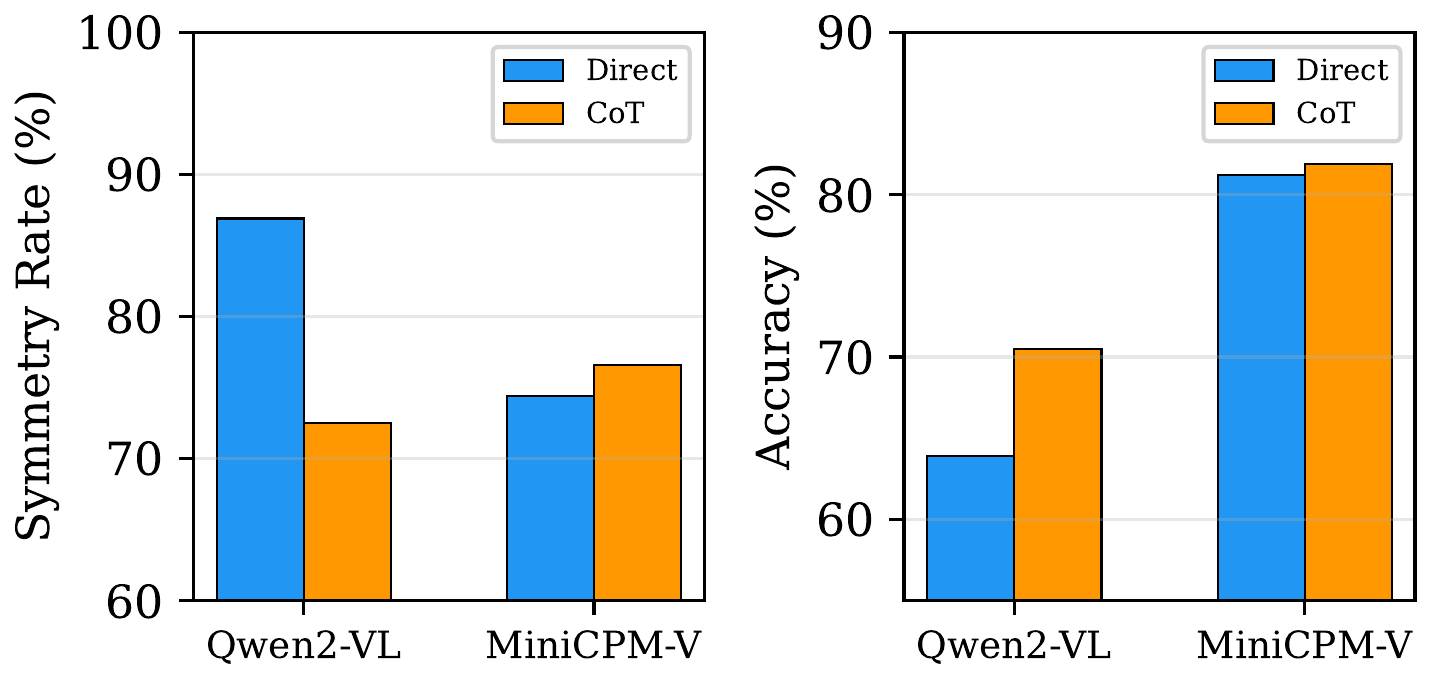 Effect of chain-of-thought prompting on consistency metrics. CoT helps MiniCPM-V on both fronts but hurts Qwen2-VL’s symmetry while improving its accuracy.
Effect of chain-of-thought prompting on consistency metrics. CoT helps MiniCPM-V on both fronts but hurts Qwen2-VL’s symmetry while improving its accuracy.
| Model | Accuracy (Direct → CoT) | Symmetry (Direct → CoT) |
|---|---|---|
| Qwen2-VL-7B | 63.9 → 70.5 (+6.6pp) | 86.9 → 72.5 (-14.4pp) |
| MiniCPM-V | 81.2 → 81.9 (+0.7pp) | 74.4 → 76.6 (+2.2pp) |
For Qwen2-VL, CoT improves accuracy but hurts symmetry – step-by-step descriptions anchor differently depending on which image is described first, amplifying position bias. MiniCPM-V shows modest gains on both metrics. The divergent effects suggest CoT’s impact on consistency is architecture-dependent.
Why Does This Happen?
Symmetry violations arise because VLMs process multi-image inputs sequentially through autoregressive generation. The model anchors on the first image and evaluates the second relative to it. Reverse the order, and the anchor changes, potentially flipping the judgment. This is the visual analogue of position bias documented in language-only settings.
One might expect internal entity-tracking mechanisms – “binding IDs” that link entities to attributes – to mitigate this. But our results suggest these mechanisms are optimized for within-sequence entity tracking (coreference), not cross-image identity comparison.
Transitivity violations are a structural limitation of pointwise inference. Each query is processed independently with no mechanism to propagate identity constraints across a graph of pairwise comparisons.
Implications
These findings have direct practical consequences:
- Forensics/security: A re-ID system that violates symmetry produces different results depending on which image is the query vs. reference – unacceptable in identity-sensitive applications.
- Multi-camera tracking: Chaining identity judgments across camera views will produce contradictory conclusions if transitivity is violated.
- Mitigation: VLM-based re-ID systems should be supplemented with post-hoc consistency enforcement, such as constraint propagation over the pairwise judgment graph.
More broadly: if VLMs cannot maintain logical consistency on a task as simple as binary identity judgment, what does this imply about their reliability on more complex reasoning tasks?
Citation
If you find this work useful, please cite:
@inproceedings{upadhyay2026vlmreid,
title={Are {VLM} Identity Judgments Logically Consistent? Evaluating Symmetry, Chain-of-Thought, and Transitivity in Person Re-Identification},
author={Upadhyay, Alok},
booktitle={ICLR 2026 Workshop on Logical Reasoning of Large Language Models},
year={2026},
url={https://openreview.net/forum?id=TooGolEUdv}
}
Accepted at the ICLR 2026 Workshop on Logical Reasoning of Large Language Models. Full paper and code available at the links above.