Alok Upadhyay | February 2026
TL;DR: We test whether LLM recommenders are logically rational by checking four classical preference axioms from social choice theory. All four models violate every axiom – IIA violations hit 30–59%, contraction consistency violations reach 37–65% – yet pairwise axioms like transitivity stay below 13%. This pairwise-vs-set-based dichotomy is consistent across all models.
Paper: Do LLM Recommenders Obey Preference Axioms? (ICLR 2026 Workshop on Logical Reasoning of LLMs)
Code: github.com/alok-upadhyay/llm-recsys-axioms
The Question
LLMs are increasingly used as zero-shot recommender systems – you describe your preferences, and the model suggests what to watch, read, or buy. But are these recommendations logically rational?
Classical social choice theory has a precise answer for what “rational” means: a recommender’s choices should satisfy basic preference axioms. If you prefer A over B and B over C, you should prefer A over C (transitivity). If you’d recommend movie A over movie B, adding a third movie to the menu shouldn’t flip that preference (independence of irrelevant alternatives).
We tested whether LLM recommenders satisfy these axioms. They don’t.
Why This Matters
LLM-based recommendations are evaluated almost exclusively on accuracy – does the model suggest items the user would like? But accuracy misses a critical failure mode: a model can recommend good items while making incoherent choices.
Consider a movie recommendation pipeline with a retrieval stage (narrowing 1,000 candidates to 50) followed by an LLM re-ranker. If the LLM violates contraction consistency, its top recommendation from the full set might not be its top recommendation from the filtered subset. The retrieval stage and re-ranking stage would silently contradict each other.
The Axioms
We test four foundational axioms from social choice theory:
1. Transitivity: If $A \succ B$ and $B \succ C$, then $A \succ C$. The most basic requirement for a coherent preference ordering.
2. Independence of Irrelevant Alternatives (IIA): The relative ranking of $A$ and $B$ should not change when a new item $D$ is added to the menu. Adding Inception to the list shouldn’t flip whether the model recommends The Matrix over Blade Runner.
3. Sen’s $\alpha$ (Contraction Consistency): If $x \in C(S)$ and $T \subseteq S$ with $x \in T$, then $x \in C(T)$. Narrowing the options shouldn’t dethrone the winner.
4. Sen’s $\beta$ (Expansion Consistency): If $x, y \in C(S)$, $S \subseteq T$, and $y \in C(T)$, then $x \in C(T)$. Expanding the menu shouldn’t create asymmetries between previously tied items.
The Setup
We constructed realistic recommendation scenarios from MovieLens-100K (100K ratings, 943 users, 1,682 movies):
- 30 users stratified across activity levels, each with 50+ ratings
- User profiles in each prompt: top-10 highest-rated movies (4–5 stars) and bottom-5 lowest-rated movies (1–2 stars), with genre information
- Position randomization: three independently randomized item orderings with majority-vote outcomes to control for position bias
| Model | Parameters |
|---|---|
| Llama-3.1-8B-Instruct | 8B |
| Mistral-7B-Instruct-v0.3 | 7B |
| Qwen2.5-7B-Instruct | 7B |
| Phi-3.5-mini-Instruct | 3.8B |
All models served locally on a single NVIDIA RTX 3090 at fp16 precision, temperature 0.
The Results
Every model violates every axiom. But the pattern of violations is remarkably consistent:
| Model | Transitivity | IIA | Sen’s $\alpha$ | Sen’s $\beta$ |
|---|---|---|---|---|
| Llama-3.1-8B | 13.0% | 30.0% | 37.3% | 5.0% |
| Mistral-7B | 9.3% | 44.1% | 65.2% | 4.6% |
| Qwen2.5-7B | 5.7% | 58.7% | 53.0% | 6.3% |
| Phi-3.5-mini | 4.7% | 35.0% | 37.7% | 3.7% |
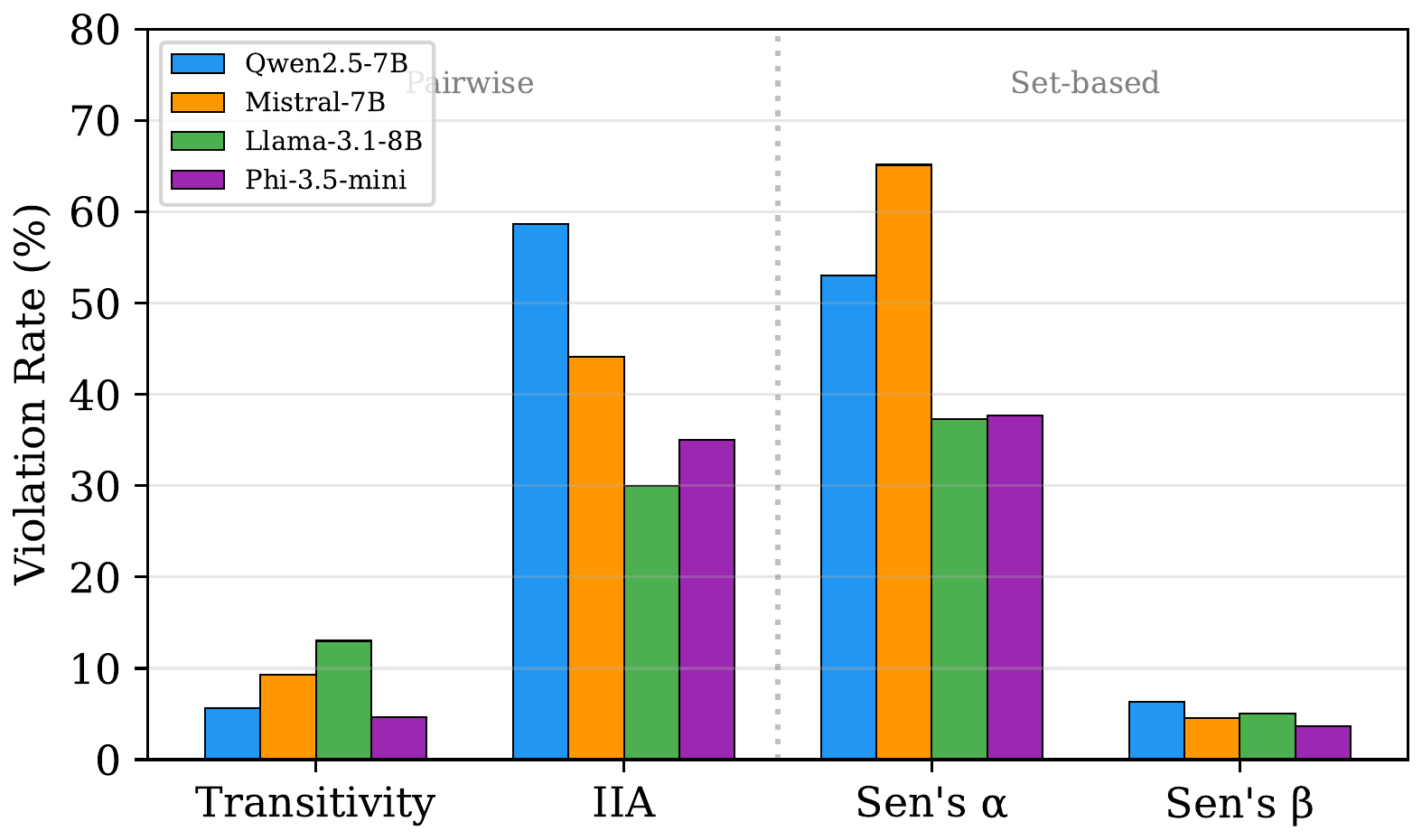 Axiom violation rates across all four models. A clear dichotomy emerges: pairwise axioms (transitivity, Sen’s beta) stay below 13%, while set-based axioms (IIA, Sen’s alpha) exceed 30–65%.
Axiom violation rates across all four models. A clear dichotomy emerges: pairwise axioms (transitivity, Sen’s beta) stay below 13%, while set-based axioms (IIA, Sen’s alpha) exceed 30–65%.
The Pairwise-vs-Set-Based Dichotomy
The most striking finding is the consistent gap between two classes of axioms:
- Pairwise axioms (transitivity + Sen’s $\beta$): < 13% violations across all models
- Set-based axioms (IIA + Sen’s $\alpha$): 30–65% violations across all models
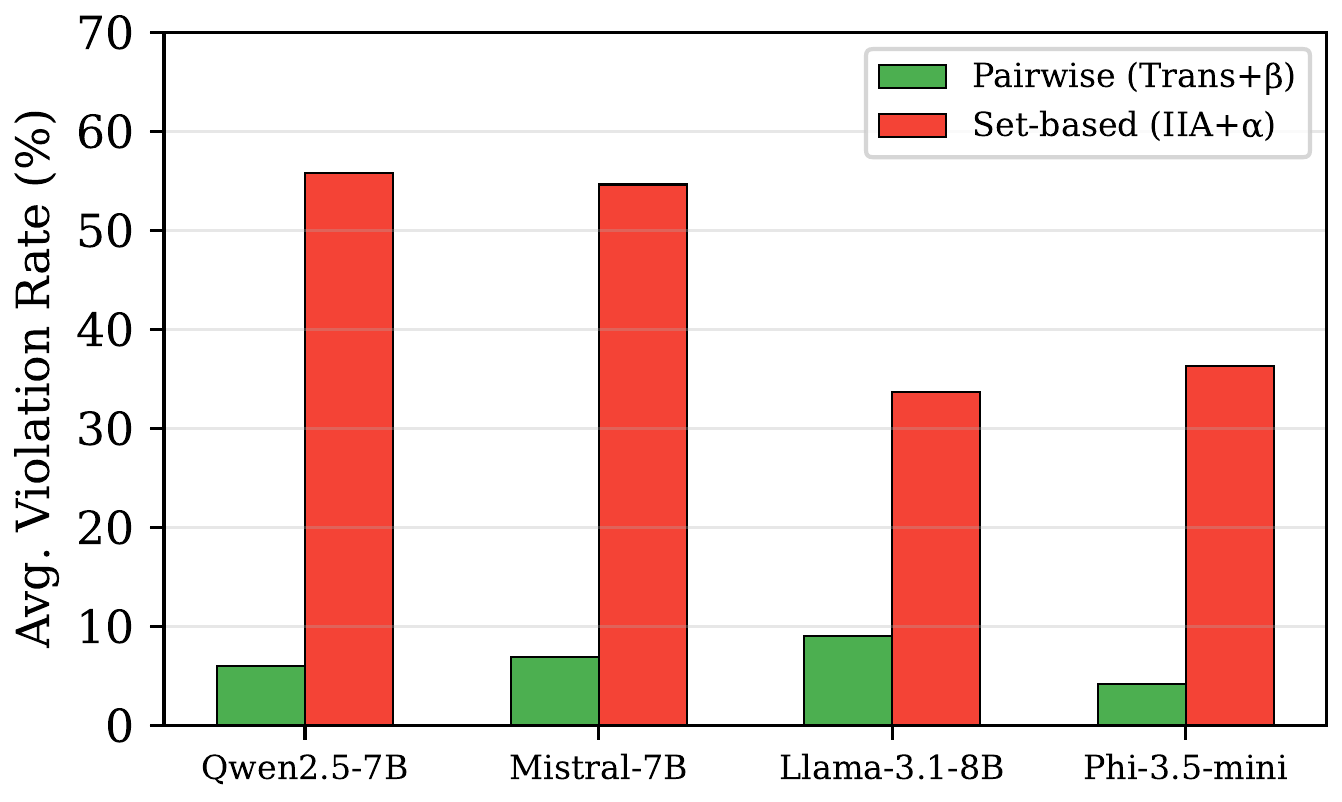 Average violation rates for pairwise axioms vs. set-based axioms. The gap is consistent across all four models, suggesting a structural property of autoregressive generation rather than a model-specific weakness.
Average violation rates for pairwise axioms vs. set-based axioms. The gap is consistent across all four models, suggesting a structural property of autoregressive generation rather than a model-specific weakness.
LLMs can maintain stable preferences when comparing two items head-to-head. But when asked to choose from a set – especially when the set composition changes – their choices become incoherent. This makes sense mechanistically: autoregressive generation processes items sequentially, and the attention distribution over a varying-size context creates context-dependent representations that shift with menu composition.
What This Means in Practice
IIA violations (30–59%) mean that adding a new movie to the candidate list can unpredictably reshuffle the entire recommendation. A user browsing a catalog could see completely different top picks depending on which items happen to be on the page.
Contraction consistency violations (37–65%) are particularly dangerous for cascaded pipelines. If a retrieval stage narrows candidates from 1,000 to 50, and a re-ranking LLM then picks from that subset, the final recommendation may not be what the LLM would have chosen from the full set. The pipeline’s output depends on an arbitrary filtering boundary.
Transitivity is (mostly) fine. The good news: pairwise comparisons are relatively stable. If you only need to compare two items at a time, LLMs are reasonably coherent. This suggests that pairwise tournament-style recommendation architectures may be more robust than set-based ranking.
Implications for System Design
-
Prefer pairwise architectures. Since LLMs maintain stable pairwise preferences, tournament-style or pairwise-comparison pipelines may yield more consistent recommendations than asking the model to rank a full set.
-
Be cautious with cascaded filtering. High contraction consistency violations mean that narrowing candidate sets can silently change the outcome. Consider re-evaluating top candidates against each other rather than trusting set-based rankings through pipeline stages.
-
Don’t assume menu independence. Adding or removing items from a recommendation context can flip preferences for unrelated items. Recommendation displays should be tested for sensitivity to catalog composition.
Citation
If you find this work useful, please cite:
@inproceedings{upadhyay2026recsysaxioms,
title={Do {LLM} Recommenders Obey Preference Axioms? Testing Logical Rationality in {LLM}-Based Recommendation},
author={Upadhyay, Alok},
booktitle={ICLR 2026 Workshop on Logical Reasoning of Large Language Models},
year={2026},
url={https://openreview.net/forum?id=VACHZaCyb9}
}
Accepted at the ICLR 2026 Workshop on Logical Reasoning of Large Language Models. Full paper and code available at the links above.